首页
Python中文网
在线手册
Python入门
Linux教程
Python高级教程
登录
注册
用户名
Email
自动登录
找回密码
密码
登录
立即注册
扫一扫,访问微社区
只需一步,快速开始
论坛
BBS
Python教程
在线手册
Python入门
Linux教程
Python高级教程
Python函数详解
搜索
本版
帖子
用户
道具
勋章
任务
设置
退出
Python论坛 - 国内最好的Python中文社区
»
论坛
›
技术交流
›
python问答 - 求助悬赏区 Help!
›
爬虫抓取失败的问题,url无误,抓取的内容和网页源... ...
返回列表
查看:
4368
|
回复:
1
[求助]
爬虫抓取失败的问题,url无误,抓取的内容和网页源...
李复唐
当前离线
积分
1
1
主题
1
帖子
1
积分
贫民
贫民, 积分 1, 距离下一级还需 59 积分
贫民, 积分 1, 距离下一级还需 59 积分
积分
1
发消息
李复唐
发表于 2018-2-24 11:06:49
|
显示全部楼层
|
阅读模式
1
威望
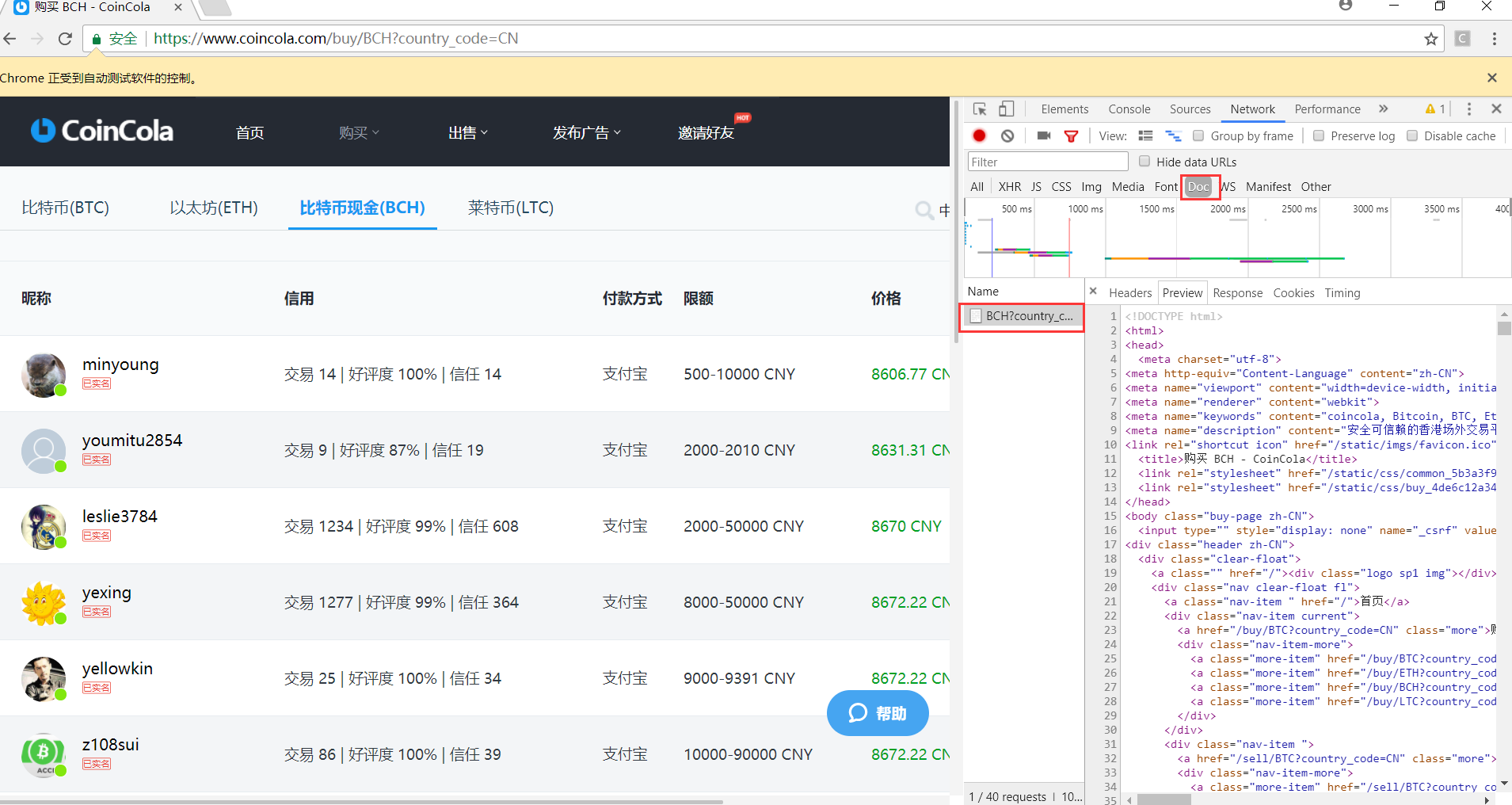
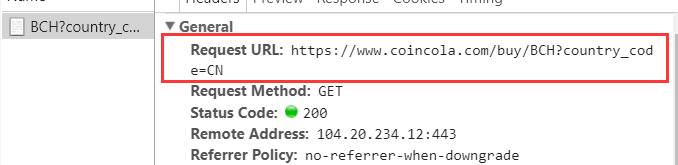
https://www.coincola.com/buy/BCH?country_code=CN,网址也没有问题
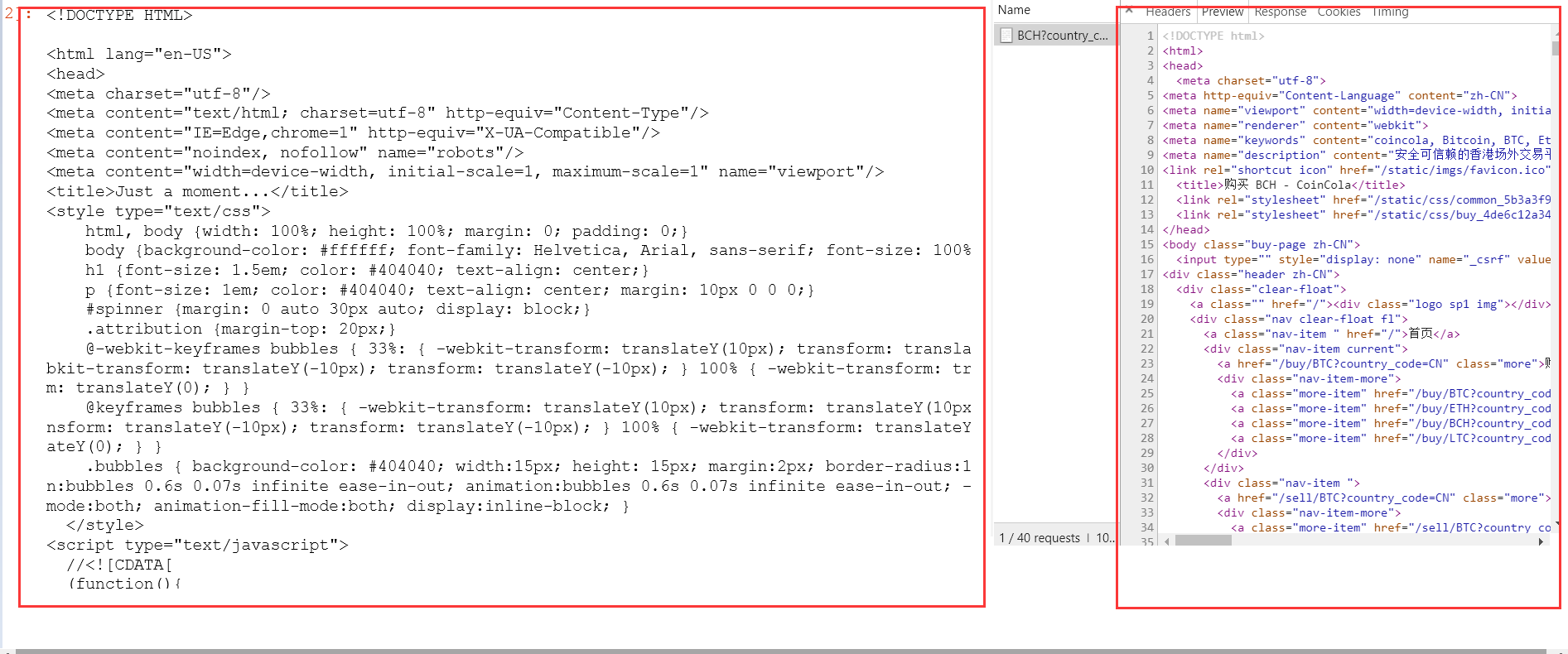
为什么,我抓取的内容和网页源码,不一致
请大家给点建议
我来回答
回复
使用道具
举报
一条可怜的狗
当前离线
积分
1
0
主题
1
帖子
1
积分
贫民
贫民, 积分 1, 距离下一级还需 59 积分
贫民, 积分 1, 距离下一级还需 59 积分
积分
1
发消息
一条可怜的狗
发表于 2018-2-25 10:37:22
|
显示全部楼层
我自己尝试了一下目标网站,然后可以获得。
我不清楚你怎么写的代码。我把我自己的贴一下。
import requestes
headers = {'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36',
'Referer':'https://www.coincola.com/buy/BCH?country_code=CN'}
res = requests.get(url, headers = headers)
print(res.text)
回复
使用道具
举报
返回列表
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
本版积分规则
发表回复
回帖后跳转到最后一页
快速回复
返回顶部
返回列表